





PRODUCT
异步缓存(M2DB)产品一、背景
在电信行业,随着业务规模的不断扩大和复杂性的增加,计费批价核心系统面临着诸多挑战,特别是在内存管理方面。目前,系统中存在着多个独立应用副本,它们往往将大量的共性数据,如产品参数、网络配置等,重复加载至各自的内存空间中,这不仅导致了内存资源的极大浪费,还增加了系统维护的复杂性和成本。
为了应对这一挑战,异步缓存产品通过引入的内存管理技术和高效的索引机制,旨在实现共性数据的集中存储和快速访问,从而显著降低内存使用量,并提升数据处理效率。
二、产品概述
M2DB(异步缓存)旨在提供高性能、低延迟和简单部署的解决方案。通过利用共享内存技术,它极大地提升了数据访问速度和吞吐量,适用于需要快速数据访问的应用场景。
产品架构
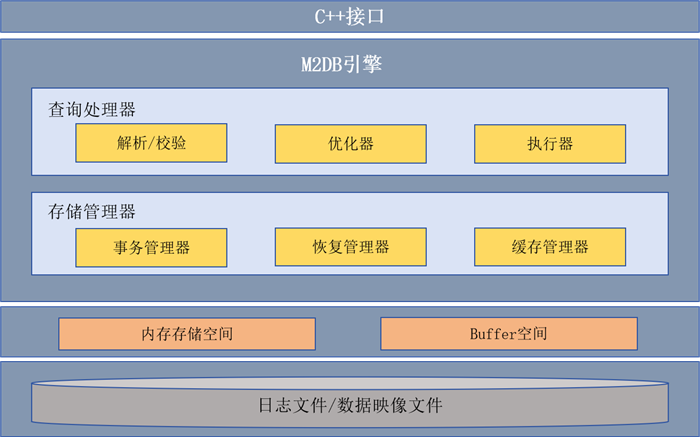
类型
支持的对象
备注
对外接口
自定义的C++接口
自定义的类SQL
SQL
支持对象
table
index
sequence
数据类型
字符
char
整型
int
long
DML操作
select
insert
M2DB只有动态数据支持insert / delete / update,静态数据不支持
delete
update
DDL操作
create table
create index
create sequence
drop table
drop index
drop sequence
表达式
聚集函数
max
min
sum
avg
count
普通函数
abs
acmax
acmin
正则表达式函数
regexp_like
其它
rowid
查询条件
ALL/NOT IN
比较
=
!=
>
>=
<>
<=
实例ID
磁盘Data store
多实例支持
工具与功能
工具
M2DB数据二进制文件导入、导出
物理库数据导入、导出
M2DB二进制文件转化为ASCII文件
内存占用估算
M2DB状态打印
M2DB与物理库数据一致性稽核
hash索引hash冲突分析
查看锁状态、手工解锁
核心功能
同步
手动、自动全量刷新(物理库至M2DB)
自动增量刷新(物理库至M2DB)
多表关联查询
表记录数或索引记录数使用百分比达到阈值
表数据块或者索引数据块页数使用百分比达到阈值
动态数据内存使用百分比达到阈值
静态数据内存使用百分比达到阈值
自动全量刷新成功/失败
手工全量刷新成功/失败
复制冲突解决
创建M2DB实例成功/失败
M2DB数据字典不一致
M2DB表和索引数据不一致
M2DB与
物理库记录总数不一致
M2DB记录缺失
字段内容不一致
M2DB数据冗余
增量刷新被强制kill掉时,自动拉起
全量定时刷新被强制kill掉时,自动拉起
关键技术
双份内存无锁机制: 使用双份内存结构和无锁设计,实现高效的并发读写操作,避免了传统锁机制的性能瓶颈,提升了系统的吞吐量和响应速度。
多实例控制: 支持多个数据库实例的并行运行和管理,每个实例独立运作,互不干扰,提供了灵活的部署和扩展选项。
内存优化:通过优化字段结构顺序和字节对齐方式,实现了内存使用效率的最大化,为用户提供了更加高效和可靠的数据库解决方案。
三、产品特性
高性能:
利用共享内存技术,实现数据的高速存取,降低I/O延迟。
高并发:
支持大量并发用户同时访问,保证系统的稳定性和响应速度。
易用性:
提供标准的SQL接口,用户无需关心底层实现,即可轻松进行数据的增删改查。
部署简单:
配置简单,易于部署和管理,不需要复杂的存储配置和调优。
四、性能基准测试
双份内存表(doubleReadOnly)与单份内存表(singleReadOnly)性能

动态表(wiriteThroughNotTran)性能

五、应用场景
实时分析和报告:适用于需要实时生成和查询大量数据的分析和报告系统。
高频率数据更新: 适用于需要快速数据写入和更新的应用,如实时监控系统和交易处理系统。
缓存加速:可作为缓存系统的后端存储,提升缓存数据的访问速度和响应时间。
嵌入式应用:适用于需要将数据库嵌入到应用程序中,以提供本地数据存储和管理功能。